Convolutional Neural Networks: Guide to Mastering CNNs in 2025
Convolutional neural networks (CNNs) have emerged as the backbone of modern computer vision, powering applications like image classification, object detection, facial recognition, and even self-driving cars. This guide will take you on a journey into the world of CNNs, explaining their architecture, inner workings, and the impact they have on various industries.
What are Convolutional Neural Networks?
Convolutional Neural Networks (CNNs) are a specialized type of artificial neural network designed to process data with a grid-like topology, such as images. Inspired by the visual cortex of animals, CNNs excel at recognizing patterns and features within images, making them ideal for tasks like identifying objects, classifying scenes, and even generating images themselves.
The Architecture of a CNN
Convolutional Neural Network consists of multiple layers like the input layer, Convolutional layer, Pooling layer, and fully connected layers.
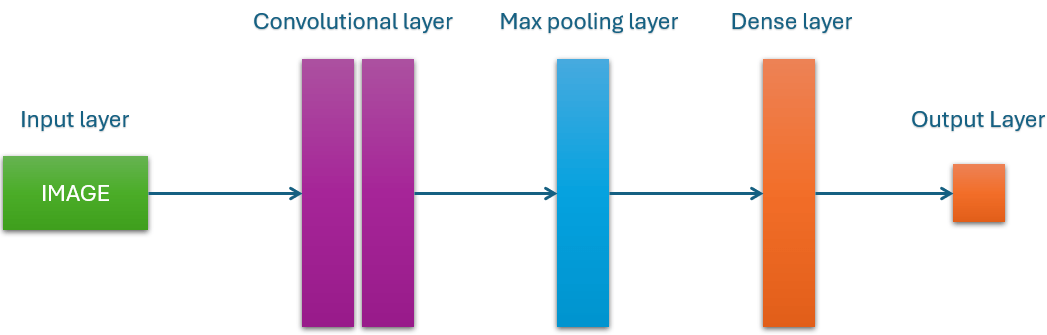
Simple CNN Architecture
Let’s break down the architecture of a Convolutional Neural Network (CNN):
1. Input Layer:
- Purpose: The input layer is the gateway for the raw image data. It takes in the pixel values of the image, usually in the form of a 3D array (height x width x channels), where the channels represent the color components (e.g., RGB).
- Example: A 28×28 pixel grayscale image would be represented as a 28x28x1 array in the input layer.
2. Convolutional Layers:
- Purpose: This is where the magic of feature extraction happens. Each convolutional layer has multiple filters (kernels) that slide across the input image, performing element-wise multiplication and summing the results.
- Filters: These filters are small matrices of numbers that are learned during training. Each filter detects a specific feature in the image, such as edges, corners, or textures.
- Feature Maps: The output of a convolutional layer is a set of feature maps. Each feature map represents the presence and intensity of a particular feature across the image.
- Key Points:
- Stride: Determines how much the filter moves at each step. A larger stride means the filter skips over more pixels, resulting in smaller feature maps.
- Padding: Adding zeros around the borders of the input image to ensure that the output feature maps have the same dimensions as the input.
3. Activation Function:
- Purpose: Activation functions introduce non-linearity into the network. This is crucial because real-world data is rarely linear. Without activation functions, the CNN would only be able to learn linear relationships, severely limiting its capabilities.
- Common Choices:
- ReLU (Rectified Linear Unit): The most popular choice due to its simplicity and efficiency.
- Sigmoid: Used primarily in the final layer for binary classification tasks.
- Tanh: Similar to sigmoid but outputs values between -1 and 1.
4. Pooling Layers:
- Purpose: Pooling layers reduce the spatial dimensions of the feature maps, which helps reduce computational complexity and prevent overfitting. They also make the network more robust to small variations in the input image.
- Common Types:
- Max Pooling: Takes the maximum value from each region of the feature map.
- Average Pooling: Averages the values in each region.
5. Fully Connected Layers:
- Purpose: These layers are typical neural network layers where each neuron is connected to every neuron in the previous layer. They take the flattened output of the convolutional and pooling layers and perform classification or regression tasks.
- Classification: Assign a label to the input image (e.g., “cat,” “dog,” “car”).
- Regression: Predict a continuous value (e.g., the price of a house).
Example CNN Architecture (LeNet-5):
- Input Layer (28x28x1)
- Convolutional Layer (6 filters of size 5×5)
- Activation Function (ReLU)
- Pooling Layer (Max Pooling, 2×2)
- Convolutional Layer (16 filters of size 5×5)
- Activation Function (ReLU)
- Pooling Layer (Max Pooling, 2×2)
- Fully Connected Layer (120 neurons)
- Activation Function (ReLU)
- Fully Connected Layer (84 neurons)
- Activation Function (ReLU)
- Fully Connected Layer (10 neurons, softmax)


How CNNs Work: The Convolution Operation
The heart of a Convolutional Neural Network (CNN) lies in its convolution operation. This process is the key to how CNNs extract meaningful features from images. Let’s break down the convolution operation step by step:
- The Filter (Kernel): A filter is a small matrix of numbers, typically 3×3 or 5×5 in size. Each number in the filter represents a weight, which determines how much emphasis the network places on different aspects of the image.
- Sliding Window: The filter slides over the input image, one pixel at a time. At each position, it overlaps with a portion of the image of the same size as the filter.
- Element-wise Multiplication: The filter’s values are multiplied by the corresponding pixel values in the image.
- Summation: The results of the element-wise multiplication are summed up to produce a single output value.
- Feature Map: This output value is stored in a new matrix called a feature map. The feature map highlights the presence and intensity of the feature that the filter is designed to detect.
The Role of Pooling
Pooling layers play a pivotal role in CNNs by performing dimensionality reduction and introducing translation invariance. These properties are essential for making CNNs efficient and effective in image recognition tasks.
Dimensionality Reduction
As convolutional layers extract features from an image, the resulting feature maps can become quite large. Pooling layers help reduce the spatial dimensions of these feature maps, making the network less computationally expensive and less prone to overfitting. This is achieved by summarizing a local region of the feature map into a single value, typically using one of the following methods:
- Max Pooling: Selects the maximum value within a pooling window (e.g., 2×2 or 3×3). This highlights the most prominent features in the region, emphasizing strong activations.
- Average Pooling: Computes the average value within the pooling window. This provides a smoother representation of the region, retaining more information but potentially diluting the strongest features.
Translation Invariance
Pooling layers introduce translation invariance, which means that the network becomes less sensitive to the precise location of features in the image. For example, if a cat is slightly shifted to the left or right in an image, max pooling will still detect the strongest “cat-like” features, regardless of their exact position. This makes the network more robust to variations in object position and improves its ability to generalize to new images.
Benefits of Pooling
- Reduced Computational Cost: Smaller feature maps require fewer parameters and computations, making the network faster to train and evaluate.
- Control Overfitting: Pooling helps prevent overfitting by reducing the number of parameters and introducing some degree of regularization.
- Improved Generalization: Translation invariance helps the network generalize to new images with slight variations in object position.
- Feature Selection: Pooling helps select the most salient features, discarding less important details.
Downsides and Alternatives
- Loss of Information: Pooling inherently discards some information, potentially sacrificing fine-grained details that could be important for certain tasks.
- Alternatives: Some researchers have explored alternative approaches, such as strided convolutions (convolutions with a step size greater than one), to achieve similar effects without the explicit pooling operation.
In practice, max pooling is often the preferred choice, especially in early layers of the CNN. Average pooling can be used in later layers when preserving more information is beneficial. The choice of pooling type and size is typically a hyperparameter that can be tuned to optimize the network’s performance.
Applications of CNNs
The applications of CNNs are vast and varied, including:
- Image Classification: Convolutional Neural Networks (CNNs) can categorize images into different classes, such as identifying whether an image contains a cat, dog, or car.
- Object Detection: Convolutional Neural Networks (CNNs) can locate and identify multiple objects within an image, along with their bounding boxes.
- Facial Recognition: CNNs power face recognition systems used for authentication, security, and personalized experiences.
- Medical Imaging: CNNs are used for disease diagnosis, tumor detection, and image segmentation in medical imaging.
- Autonomous Vehicles: CNNs are crucial for object recognition and scene understanding in self-driving cars.
The Future of CNNs: Advancements and Challenges
CNNs continue to evolve rapidly, with researchers exploring new architectures, training methods, and applications. Some of the emerging trends include:
- Attention Mechanisms: Allowing Convolutional Neural Networks (CNNs) to focus on specific parts of the input, improving performance on tasks like image captioning.
- Generative Adversarial Networks (GANs): Using CNNs to generate realistic images and other forms of data.
- Transfer Learning: Leveraging pre-trained CNNs on large datasets to solve new tasks with less training data.
Building Your Own Convolutional Neural Network (CNN)
Building a convolutional neural network from scratch requires a solid understanding of deep learning concepts and programming skills. Several popular deep learning frameworks, such as TensorFlow and PyTorch, provide tools and libraries to simplify the process.
Here’s a simplified example of building a CNN using Keras, a high-level API for TensorFlow:
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
Tips for Training CNNs
- Data Augmentation: Increase the size and diversity of your training dataset by applying random transformations like rotations, flips, and crops.
- Regularization: Techniques like dropout and weight decay can help prevent overfitting and improve generalization.
- Hyperparameter Tuning: Experiment with different learning rates, batch sizes, and network architectures to find the optimal configuration for your task.
Advantages of Convolutional Neural Networks (CNNs):
- Excellent at Feature Extraction: Convolutional Neural Networks (CNNs) excel at automatically learning and extracting relevant features from images, videos, or audio signals. This eliminates the need for manual feature engineering, a time-consuming and often error-prone process in traditional machine learning.
- Robust to Variations: Convolutional Neural Networks (CNNs) exhibit robustness to translation, rotation, and scaling transformations. This means they can recognize objects in different positions, orientations, and sizes, making them ideal for real-world applications where these variations are common.
- End-to-End Training: CNNs are trained in an end-to-end fashion, meaning they learn directly from raw input data to produce the desired output. This simplifies the model development process and eliminates the need for intermediate feature extraction steps.
- High Accuracy: CNNs have consistently achieved state-of-the-art performance in various image recognition and classification tasks. Their ability to learn complex patterns and representations from large datasets has led to significant breakthroughs in fields like computer vision and medical imaging.
- Handles Large Datasets: CNNs can effectively handle large datasets thanks to their weight-sharing mechanism and efficient computational techniques like parallel processing. This makes them well-suited for applications that involve massive amounts of image or video data.
Disadvantages of Convolutional Neural Networks (CNNs):
- Computationally Expensive: Training Convolutional Neural Networks (CNNs) can be computationally intensive, requiring powerful hardware like GPUs or TPUs. This can be a significant barrier for individuals or organizations with limited resources.
- Prone to Overfitting: Convolutional Neural Networks (CNNs) can be prone to overfitting, especially when trained on small datasets. Overfitting occurs when the model learns to memorize the training data instead of generalizing to new, unseen examples. Regularization techniques like dropout and early stopping can help mitigate this issue.
- Requires Large Labeled Datasets: CNNs typically require large amounts of labeled data to achieve good performance. Obtaining and labeling such datasets can be expensive and time-consuming.
- Black Box Nature: CNNs are often criticized for their lack of interpretability. It can be difficult to understand why a CNN makes a specific prediction, which raises concerns about their reliability and potential biases.
Frequently Asked Questions (FAQ)
Q: How do I get started with learning about Convolutional Neural Networks (CNNs)?
A: The best way to begin is by understanding the fundamentals of deep learning and neural networks. There are many excellent online courses and tutorials available on platforms like Coursera, Udacity, and edX. Once you have a solid grasp of the basics, delve into resources specifically focused on CNNs, such as textbooks like “Deep Learning with Python” by Francois Chollet or research papers from reputable sources. Experimenting with open-source code implementations can also be a great way to learn hands-on.
Q: What are the best tools and frameworks for building Convolutional Neural Networks (CNNs)?
A: Several popular deep learning frameworks offer robust tools and libraries for constructing and training CNNs:
- TensorFlow: Developed by Google, TensorFlow is a widely used open-source framework with a comprehensive ecosystem for deep learning. Its high-level API, Keras, simplifies the process of building CNN models.
- PyTorch: Known for its flexibility and dynamic computation graph, PyTorch is another popular choice for researchers and practitioners. It offers intuitive APIs and excellent debugging capabilities.
- Keras: A user-friendly, high-level API that runs on top of TensorFlow (or Theano). Keras is an excellent starting point for beginners due to its simple syntax and ease of use.
Q: What are some challenges in training Convolutional Neural Networks (CNNs)?
A: Training CNNs can be challenging due to several factors:
- Overfitting: When a CNN performs well on training data but poorly on new, unseen data, it’s likely overfitting. Regularization techniques like dropout and L2 regularization can help mitigate this issue.
- Vanishing Gradients: During training, gradients (used for updating model parameters) can become very small, hindering learning. Techniques like batch normalization and using appropriate activation functions (e.g., ReLU) can help address this.
- Computational Complexity: Training deep CNNs can be computationally expensive, requiring powerful hardware (GPUs or TPUs) and efficient algorithms.
Q: How can I improve the performance of my Convolutional Neural Network?
A: There are several strategies to enhance CNN performance:
- More Data: Generally, more labeled training data leads to better performance. Consider collecting more data or using data augmentation techniques to artificially expand your dataset.
- Hyperparameter Tuning: Experiment with different hyperparameters (learning rate, batch size, etc.) to find the optimal configuration for your specific task.
- Architecture Optimization: Explore different CNN architectures (e.g., ResNet, Inception) or try designing your own to better suit your problem.
- Transfer Learning: Leverage pre-trained models on large datasets (e.g., ImageNet) and fine-tune them for your specific task. This can save time and resources compared to training from scratch.
Q: What are some ethical considerations for using Convolutional Neural Networks (CNNs)?
A: CNNs have the potential to be used for both beneficial and harmful purposes. Some ethical concerns include:
- Bias: CNNs can inherit biases present in the training data, leading to discriminatory outcomes. It’s essential to ensure diversity and fairness in your data and to be mindful of potential biases.
- Privacy: CNNs can be used for facial recognition and surveillance, raising privacy concerns. Consider the ethical implications of how your CNN models will be used.
- Misuse: CNNs can be used to create deepfakes or manipulate images and videos, leading to misinformation and potential harm. It’s important to use CNNs responsibly and avoid malicious applications.
Q: What are some common applications of Convolutional Neural Networks (CNNs) beyond image recognition?
A: While CNNs are renowned for their prowess in image recognition, their applications extend to various domains:
- Natural Language Processing (NLP): CNNs are used for text classification, sentiment analysis, and language translation tasks.
- Time Series Analysis: CNNs can analyze time-dependent data like stock prices, weather patterns, and sensor readings.
- Drug Discovery: CNNs are employed to predict molecular properties and identify potential drug candidates.
- Recommendation Systems: CNNs can power recommendation engines by analyzing user behavior and preferences.
- Anomaly Detection: CNNs can detect anomalies in data, such as fraudulent transactions or unusual patterns in medical images.
Q: Can Convolutional Neural Networks (CNNs) be used with small datasets?
A: While CNNs typically perform best with large amounts of data, they can still be effective with smaller datasets. Techniques like transfer learning (using a pre-trained model as a starting point) and data augmentation (creating variations of existing data) can help improve performance in such cases.
Q: Are Convolutional Neural Networks (CNNs) the only type of deep learning architecture for image analysis?
A: No, CNNs are not the only option. Other architectures like Recurrent Neural Networks (RNNs) and Transformers have also shown promise in image analysis tasks. The choice of architecture often depends on the specific problem and the type of data being analyzed.
Q: How do I choose the right architecture for my Convolutional Neural Network (CNN)?
A: The choice of CNN architecture depends on several factors, including:
- Complexity of the Task: Simple tasks may require a shallower network, while complex tasks may necessitate deeper architectures.
- Computational Resources: Larger models with more parameters require more computational power to train.
- Dataset Size: The amount of training data available can influence the choice of architecture.
- Desired Accuracy and Speed: Trade-offs between accuracy and computational efficiency often need to be considered.
Q: What are some emerging trends and future directions in Convolutional Neural Network (CNN) research?
A: CNN research is a dynamic field with several exciting trends:
- Explainable AI (XAI): Developing methods to make CNNs more interpretable and explain their decision-making processes.
- Efficient Architectures: Designing CNNs that are smaller, faster, and require less energy, making them suitable for edge devices.
- Self-Supervised and Unsupervised Learning: Reducing the reliance on labeled data by exploring self-supervised and unsupervised learning techniques for CNNs.
- Domain Adaptation: Enabling CNNs to generalize better to new domains and tasks without extensive retraining.
By understanding the intricacies of convolutional neural networks (CNNs), you’ll be well-equipped to harness their immense power and contribute to the ever-evolving field of deep learning.