Tree Data Structure
Tree data structures are powerful tools for representing hierarchical relationships within data. Think of a family tree, where each person (node) is connected to their parents (parent node) and children (child nodes). This same concept applies to organizing information in computer science, enabling efficient searching, sorting, and manipulation of data in various applications. Whether you’re building a file system, designing a database index, or implementing complex algorithms, understanding tree data structures is essential for success.
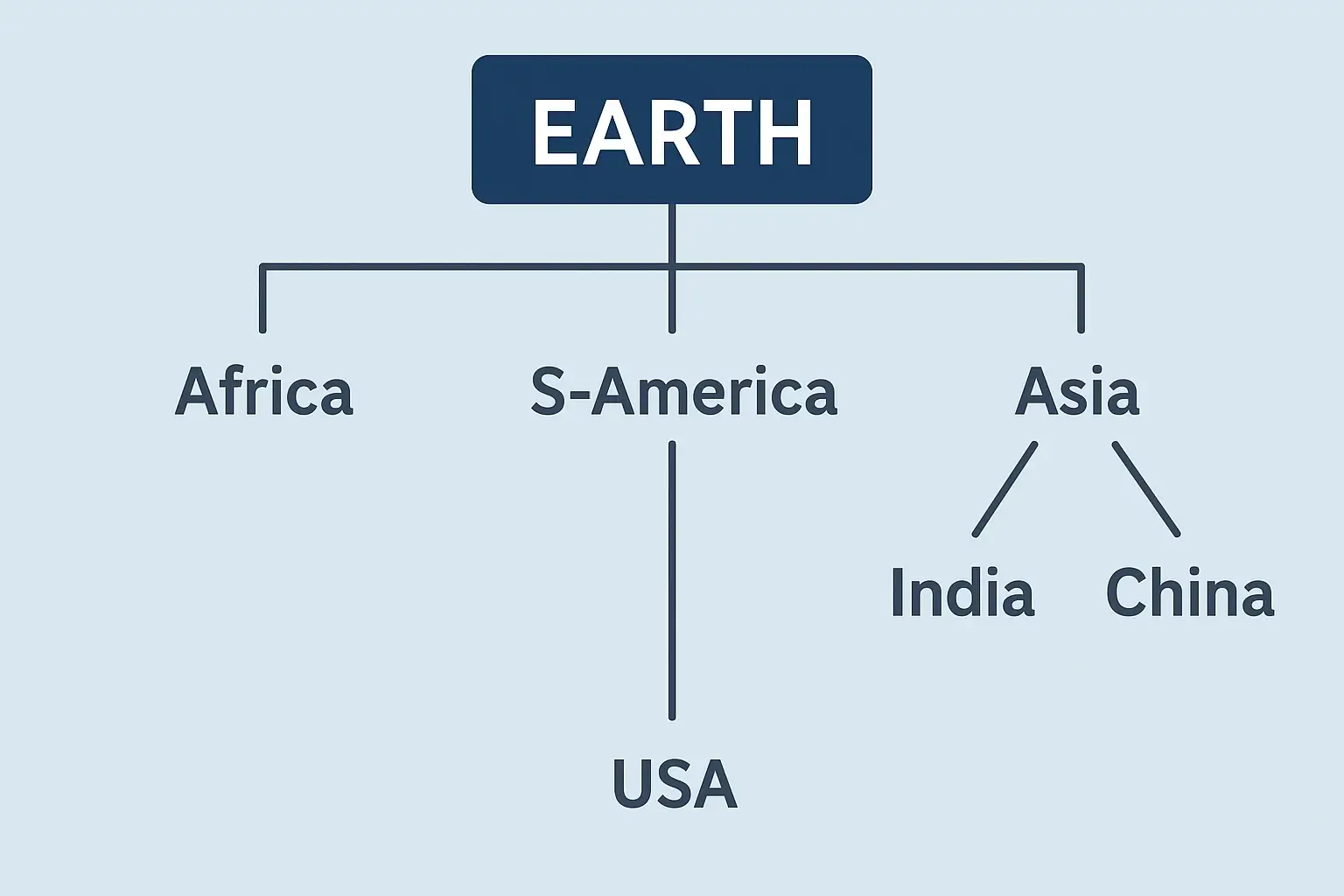
Understanding Tree Data Structure: The Basics
A tree data structure consists of nodes connected by edges, forming a hierarchical structure. The topmost node is called the root, and each node can have zero or more child nodes. Nodes without children are called leaves.
Key Terminology in Tree Data Structures
- Node: A fundamental unit of a tree that stores data and references to its children (if any).
- Root: The topmost node of the tree.
- Parent Node: A node that has one or more child nodes.
- Child Node: A node that is connected to a parent node.
- Leaf Node: A node with no children.
- Subtree: A smaller tree that is part of a larger tree.
- Depth: The number of edges from the root to a particular node.
- Height: The number of edges on the longest path from the root to a leaf.
Types of Tree Data Structure
- Binary Tree: Each node has at most two children, referred to as the left child and right child.
- Binary Search Tree (BST): A binary tree with the special property that the left child of a node has a value smaller than the node’s value, and the right child has a value greater than the node’s value. This property allows for efficient searching and sorting.
- AVL Tree: A self-balancing binary search tree where the heights of the two child subtrees of any node differ by at most one. This ensures efficient operations even in the worst case.
- B-tree: A self-balancing tree designed for efficient disk access. It’s commonly used in databases and file systems.
- Trie (Prefix Tree): Used to store strings efficiently, with each node representing a part of a string.
- Heap: A specialized tree-based structure used for priority queues, where the highest (or lowest) priority element is always at the root.
Applications of Tree Data Structure
Tree data structures are incredibly versatile and find applications in numerous domains:
- Databases: B-trees are used for indexing in databases, allowing for fast data retrieval.
- File Systems: Hierarchical file systems are organized as trees, with directories as nodes and files as leaves.
- Search Algorithms: Binary search trees and their variants enable efficient searching in sorted datasets.
- Sorting Algorithms: Heap sort and tree sort leverage tree structures for sorting data.
- Expression Evaluation: Expression trees are used to represent and evaluate mathematical expressions.
- Decision Trees: Used in machine learning for classification and regression tasks.
Choosing the Right Tree Data Structure
The best tree data structure for your application depends on your specific needs:
- Binary Search Trees: Ideal when you need to maintain sorted data and perform frequent search, insert, and delete operations.
- AVL Trees or Red-Black Trees: If balanced trees are essential for consistent performance, even in the worst case.
- B-trees: When dealing with large datasets stored on disk, B-trees provide efficient access patterns.
- Tries: Efficiently store and search strings or prefixes of strings.
- Heaps: When you need to quickly access the maximum or minimum element in a dataset.
FAQs: Tree Data Structure
Q: Are all trees binary trees?
A: No. While binary trees are common, trees can have any number of children per node.
Q: Why are balanced trees important?
A: Balanced trees ensure that search, insert, and delete operations remain efficient even in the worst-case scenarios, preventing the tree from becoming skewed and degrading performance.
Q: How are trees used in databases?
A: B-trees are used as indexes in databases, allowing for fast searching of large datasets stored on disk.
Q: Can I implement a tree using an array?
A: Yes, but it’s often more efficient to use dynamic memory allocation with pointers or references to build tree structures.
8 free, 100% client-side tools for developers — no signup, no data uploads.
Explore all tools